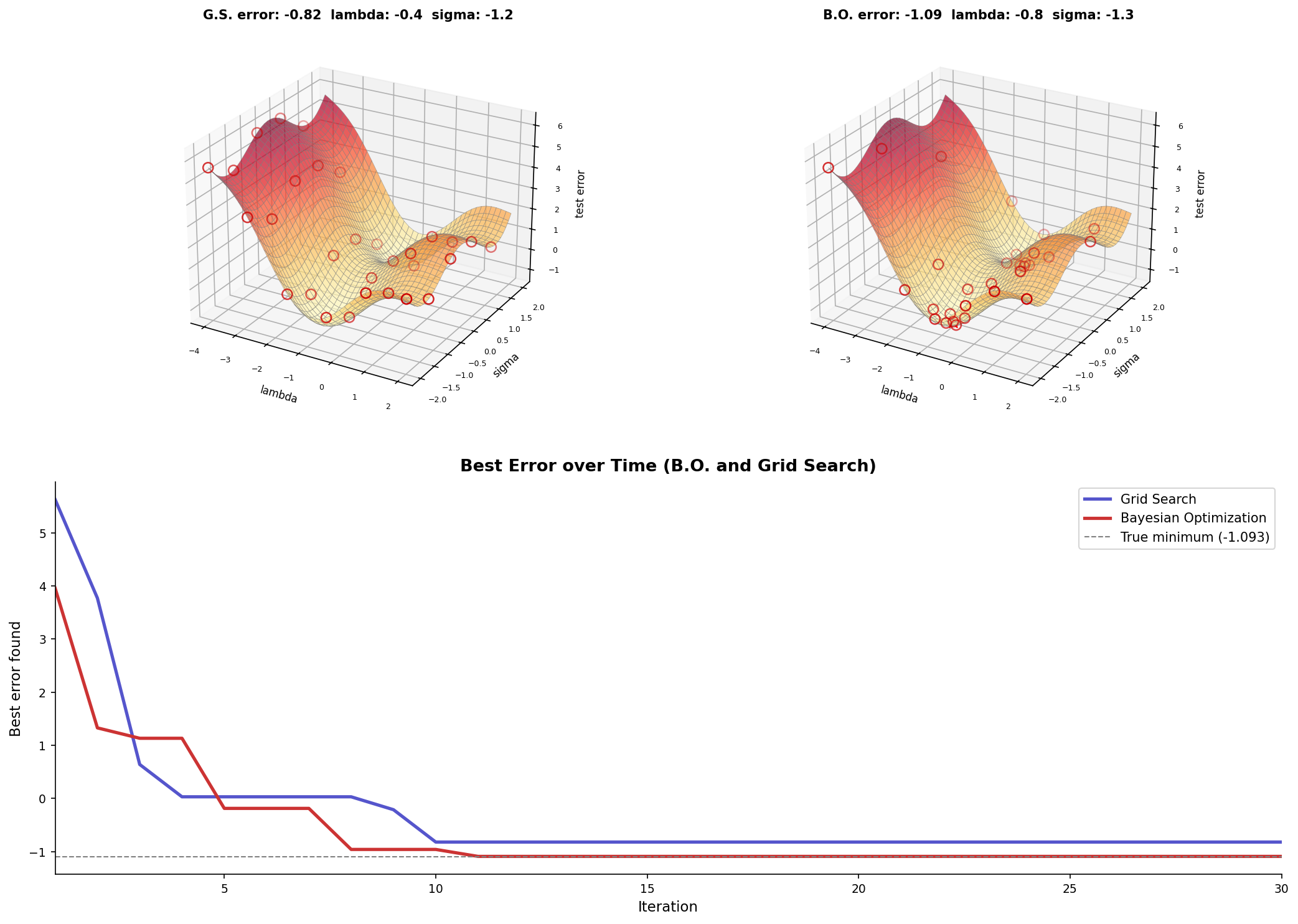
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process.kernels import Matern
from scipy.stats import norm
from scipy.optimize import minimize
from scipy.spatial.distance import cdist
class GPreg:
def __init__(self, X_train, y_train, X_plot, f, length_scale=1.0, bounds=np.array([[-1.0,2.0]]), keps=1e-8):
"""
Initialize the Gaussian Process regression model.
Args:
X_train: Initial training inputs, shape (n, 1)
y_train: Initial training targets, shape (n, 1)
X_plot: Dense grid of points for plotting, shape (m, 1). Never changes.
f: Objective function to optimize. Must accept (X, noise=...).
length_scale: Length scale parameter for the Matern kernel.
bounds: Search space bounds, shape (1, 2) e.g. np.array([[-1.0, 2.0]])
keps: Jitter added to kernel diagonal for numerical stability.
"""
self.L = length_scale
self.keps = keps
self.bounds = bounds
# store initial state so run_bo can reset between acquisition function runs
self.X_train_init = X_train
self.y_train_init = y_train
self.X_train = X_train
self.y_train = y_train
self.X_plot = X_plot # fixed dense grid for plotting, never changes
self.X_test = X_plot
self.obj_fn = f
# initialize prior mean (zero) and prior covariance over plot grid
self.muFn = self.mean_func(self.X_test)
self.Kfn = self.kernel_func(self.X_test, self.X_test, length_scale=self.L) + 1e-15*np.eye(len(self.X_test))
def mean_func(self, X):
"""
Zero mean prior function. Returns a zero vector of shape (n, 1) for n input points.
A zero mean is the standard choice when there is no prior knowledge about the function's average behavior.
"""
return np.zeros((np.size(X), 1))
def kernel_func(self, X, z, length_scale=1.0, nu=2.5):
"""
Matern kernel with nu=2.5 (twice differentiable).
Args:
X: First input array, shape (n, 1)
z: Second input array, shape (m, 1)
length_scale: Controls how quickly correlation decays with distance.
nu: Smoothness parameter. nu=2.5 means twice differentiable.
Returns:
Kernel matrix of shape (n, m).
"""
return Matern(length_scale=length_scale, nu=nu)(X, z)
def compute_posterior(self, X_test=None, rewrite=True):
"""
Compute the GP posterior mean and covariance conditioned on training data.
K is the train-train kernel matrix, K_s is train-test, K_ss is test-test.
Args:
X_test: Test points to predict at. Defaults to X_plot (the dense grid).
rewrite: If True, updates self.muFn and self.Kfn (used for plotting).
If False, returns values without touching stored state (used
inside acquisition functions during optimization).
Returns:
posterior_mean: shape (n_test, 1)
posterior_cov: shape (n_test, n_test)
"""
if X_test is None:
X_test = self.X_plot
K = self.kernel_func(self.X_train, self.X_train, length_scale=self.L) + self.keps * np.eye(len(self.X_train))
K_s = self.kernel_func(self.X_train, X_test, length_scale=self.L)
K_ss = self.kernel_func(X_test, X_test, length_scale=self.L) + self.keps * np.eye(len(X_test))
K_inv = np.linalg.inv(K)
posterior_mean = np.dot(K_s.T, np.dot(K_inv, self.y_train))
posterior_cov = K_ss - np.dot(K_s.T, np.dot(K_inv, K_s))
if rewrite:
self.muFn = posterior_mean
self.Kfn = posterior_cov
return posterior_mean, posterior_cov
def upper_confidence_bound(self, X, lambda_=1.0):
"""
Upper Confidence Bound (UCB) acquisition function.
Args:
X: Candidate point(s), shape (n, 1)
lambda_: Exploration-exploitation trade-off parameter. Larger values encourage more exploration.
Returns:
ucb: Upper confidence bound at each point in X, shape (n,)
"""
X = np.atleast_2d(X) # ensure 2D input
if X.shape[0] == 1 and X.shape[1] != 1:
X = X.T # ensure shape (n, 1) not (1, n)
mu, cov = self.compute_posterior(X, rewrite=False) # predict without overwriting plot grid posterior
mu = mu.flatten()
sigma = np.sqrt(np.maximum(np.diag(cov), 0)) # posterior standard deviation at each point
return mu + lambda_ * sigma # upper confidence bound
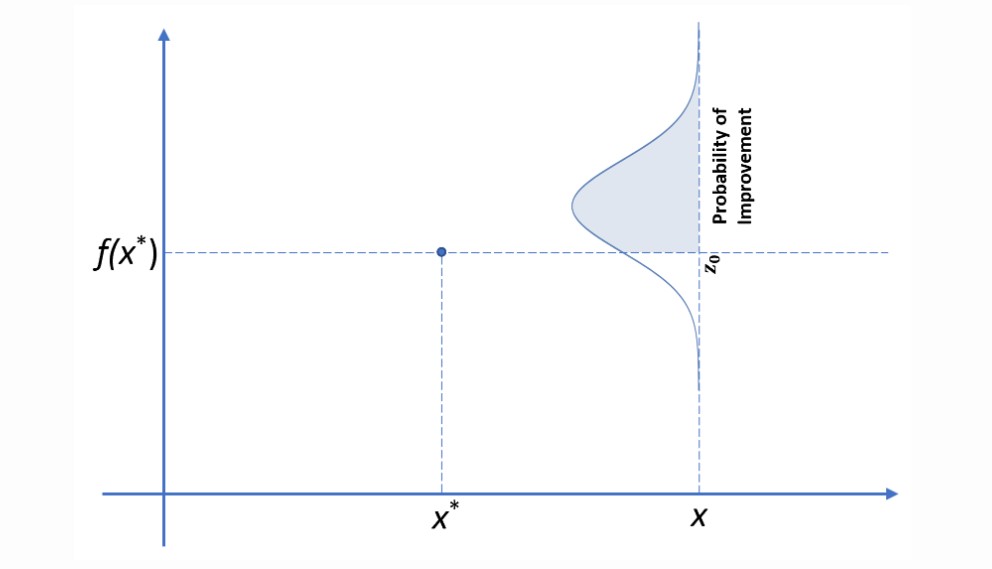
def improvement_probability(self, X, xi=0.01):
"""
Probability of Improvement (PI) acquisition function.
Args:
X: Candidate point(s), shape (n, 1)
xi: Exploration-exploitation trade-off. Larger xi = more exploration.
Returns:
pi: Probability of improvement at each point in X, shape (n,)
"""
X = np.atleast_2d(X)
if X.shape[0] == 1 and X.shape[1] != 1:
X = X.T
mu, cov = self.compute_posterior(X, rewrite=False)
mu = mu.flatten()
sigma = np.sqrt(np.maximum(np.diag(cov), 0))
mu_sample_opt = np.max(self.y_train)
with np.errstate(divide='warn'):
imp = mu - mu_sample_opt - xi
Z = imp / sigma
pi = norm.cdf(Z)
pi[sigma == 0.0] = 0.0
return pi
def expected_improvement(self, X, xi=0.01):
"""
Expected Improvement (EI) acquisition function.
Args:
X: Candidate point(s), shape (n, 1)
xi: Exploration-exploitation trade-off. Larger xi = more exploration.
Returns:
ei: Expected improvement at each point in X, shape (n,)
"""
X = np.atleast_2d(X) # ensure 2D input
if X.shape[0] == 1 and X.shape[1] != 1:
X = X.T # ensure shape (n, 1) not (1, n)
mu, cov = self.compute_posterior(X, rewrite=False)
mu = mu.flatten()
sigma = np.sqrt(np.maximum(np.diag(cov), 0))
mu_sample_opt = np.max(self.y_train)
with np.errstate(divide='warn'):
imp = mu - mu_sample_opt - xi
Z = imp / sigma
ei = imp * norm.cdf(Z) + sigma * norm.pdf(Z)
ei[sigma == 0.0] = 0.0
return ei
def propose_location(self, acquisition, bounds, n_restarts=25):
"""
Find the next sampling location by maximizing the acquisition function.
Args:
acquisition: Acquisition function to maximize (e.g. expected_improvement)
bounds: Search space bounds, shape (1, 2)
n_restarts: Number of random restarts for the optimizer.
Returns:
X_next: Next proposed sampling location, shape (1, 1)
"""
dim = self.X_train.shape[1] # feature dimension
min_val = np.inf
min_x = None
def min_obj(X):
# negate because scipy.optimize.minimize minimizes
return -acquisition(X)
for x0 in np.random.uniform(bounds[:,0], bounds[:,1], size=(n_restarts, dim)):
res = minimize(min_obj, x0=x0, bounds=bounds, method='L-BFGS-B')
if res.fun < min_val:
min_val = res.fun
min_x = res.x
return min_x.reshape(-1, 1)
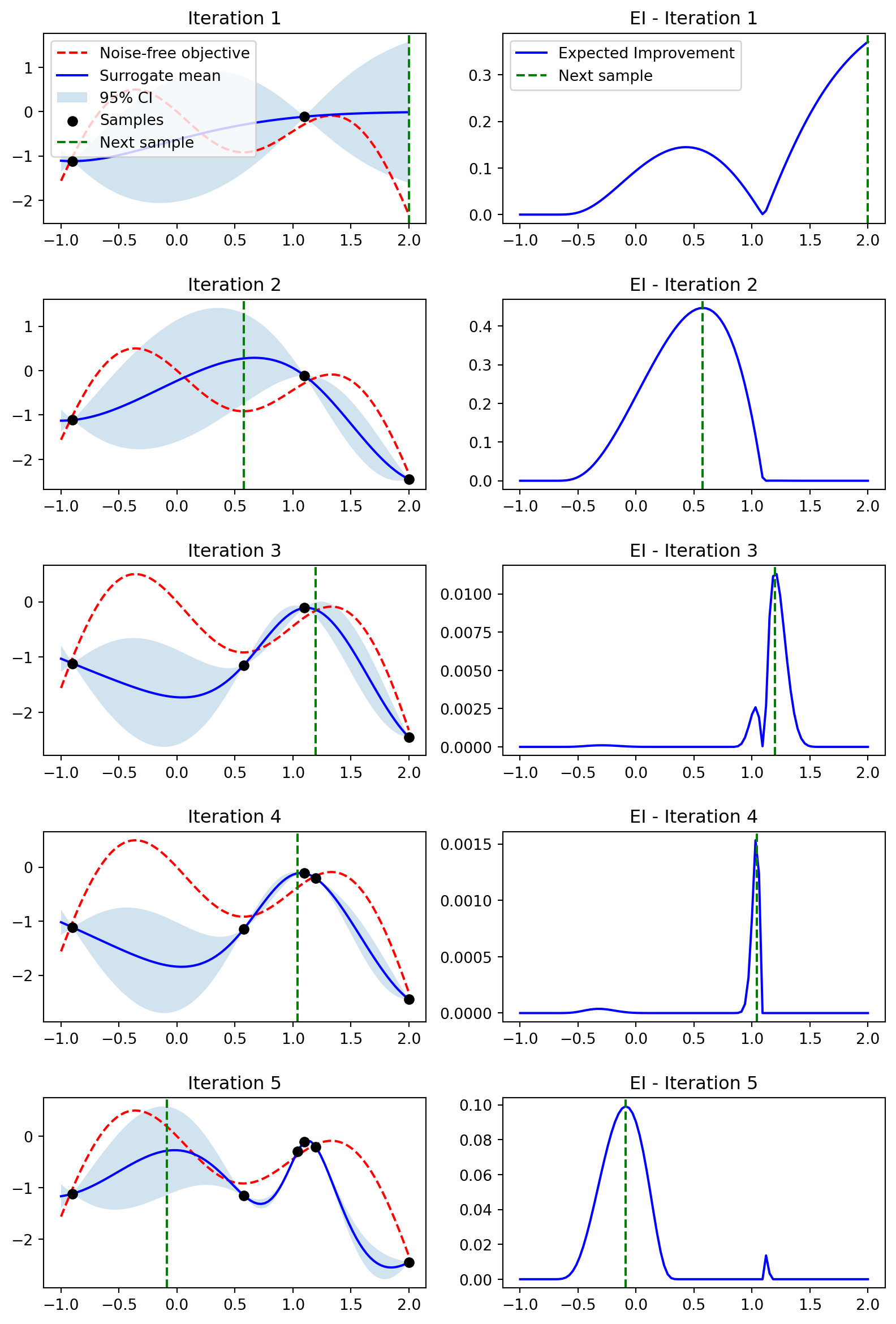
def plot_approximation(self, X_next, Y_next, i, n_iter):
"""
Plot the GP surrogate mean, uncertainty band, observations, and next sample.
Displays:
- Red dashed line: noise-free true objective (ground truth)
- Blue line: GP posterior mean (surrogate)
- Blue band: 95% credible interval (+/- 1.96 * sigma)
- Black dots: Noisy observations seen so far
- Green dashed: Next proposed sampling location
Args:
X_next: Next proposed point, shape (1, 1)
Y_next: Objective value at X_next
i: Current iteration index (0-based)
n_iter: Total number of iterations (for subplot layout)
"""
mu = self.muFn.flatten()
sigma = np.sqrt(np.maximum(np.diag(self.Kfn), 0))
X_plot = self.X_plot.flatten()
plt.subplot(n_iter, 2, 2 * i + 1)
plt.plot(X_plot, self.obj_fn(self.X_plot, noise=0), 'r--', label='Noise-free objective')
plt.plot(X_plot, mu, 'b-', label='Surrogate mean')
plt.fill_between(X_plot, mu - 1.96*sigma, mu + 1.96*sigma, alpha=0.2, label='95% CI')
plt.scatter(self.X_train, self.y_train, c='black', zorder=10, label='Samples')
plt.axvline(x=X_next, color='g', linestyle='--', label='Next sample')
plt.title(f'Iteration {i+1}')
if i == 0:
plt.legend()
def plot_acquisition(self, X_next, i, n_iter):
"""
Plot the EI acquisition function curve over the search space.
Args:
X_next: Next proposed point (shown as vertical dashed line)
i: Current iteration index (0-based)
n_iter: Total number of iterations (for subplot layout)
"""
ei = self.expected_improvement(self.X_plot)
X_plot = self.X_plot.flatten()
plt.subplot(n_iter, 2, 2 * i + 2)
plt.plot(X_plot, ei, 'b-', label='Expected Improvement')
plt.axvline(x=X_next, color='g', linestyle='--', label='Next sample')
plt.title(f'EI - Iteration {i+1}')
if i == 0:
plt.legend()
def run_bo(self, acquisition=None, n_iter=10, store_traces=False, n_restarts=25):
"""
Run the Bayesian Optimization loop.
At each iteration:
1. Compute the GP posterior over the plot grid
2. Find the next point by maximizing the acquisition function
3. Evaluate the objective at the next point
4. Update training data and repeat
Always resets X_train and y_train to the initial state before running,
so multiple calls (e.g. in compare_acquisition) start from the same data.
Args:
acquisition: Acquisition function to use. Defaults to expected_improvement.
n_iter: Number of BO iterations.
store_traces: If False, plots each iteration as it runs (single-function mode).
If True, stores iteration data as a list of dicts for later
plotting (used by compare_acquisition).
n_restarts: Number of restarts for propose_location.
Returns:
traces (only when store_traces=True): list of dicts, one per iteration,
each containing mu, sigma, X_next, Y_next, acq_vals, X_train, y_train.
"""
if acquisition is None:
acquisition = self.expected_improvement
# reset to initial state so runs are always comparable
self.X_train = self.X_train_init.copy()
self.y_train = self.y_train_init.copy()
traces = []
if not store_traces:
plt.figure(figsize=(10, n_iter * 3))
plt.subplots_adjust(hspace=0.4)
for i in range(n_iter):
mu, cov = self.compute_posterior(rewrite=True)
sigma = np.sqrt(np.maximum(np.diag(cov), 0))
X_next = self.propose_location(acquisition, self.bounds, n_restarts=n_restarts)
Y_next = self.obj_fn(X_next)
acq_vals = acquisition(self.X_plot) # acquisition values over full plot grid
if store_traces:
traces.append({
'mu': mu.flatten(),
'sigma': sigma,
'X_next': X_next,
'Y_next': Y_next,
'acq_vals': acq_vals,
'X_train': self.X_train.copy(),
'y_train': self.y_train.copy()
})
else:
self.plot_approximation(X_next, Y_next, i, n_iter)
self.plot_acquisition(X_next, i, n_iter)
self.X_train = np.vstack((self.X_train, X_next))
self.y_train = np.vstack((self.y_train, Y_next))
if not store_traces:
plt.show()
else:
# restore initial state after trace collection
self.X_train = self.X_train_init.copy()
self.y_train = self.y_train_init.copy()
return traces
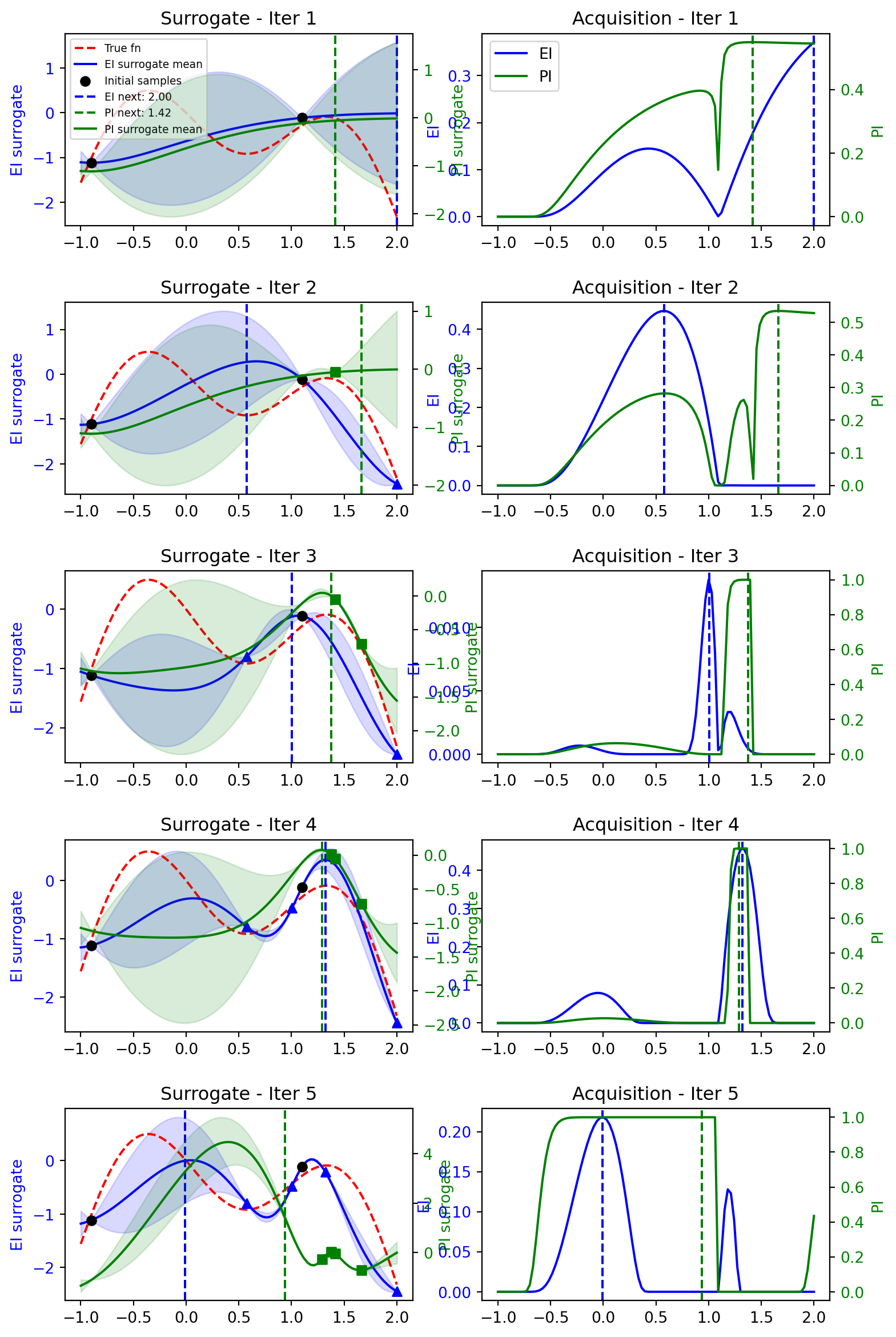
def compare_acquisition(self, n_iter):
"""
Compare EI and PI acquisition functions side by side.
Runs the full BO loop twice from the same initial data and plots both
surrogate means and acquisition curves together at each iteration
using dual y-axes for readability.
Args:
n_iter: Number of BO iterations to run and display.
"""
# run both acquisition functions from same initial state
traces_ei = self.run_bo(self.expected_improvement, n_iter, store_traces=True)
traces_pi = self.run_bo(self.improvement_probability, n_iter, store_traces=True)
X_plot = self.X_plot.flatten()
plt.figure(figsize=(9, n_iter * 3))
plt.subplots_adjust(hspace=0.4)
for i in range(n_iter):
ei_trace = traces_ei[i]
pi_trace = traces_pi[i]
# --- combined surrogate plot with twin axis ---
ax1 = plt.subplot(n_iter, 2, 2 * i + 1)
ax1_twin = ax1.twinx()
ax1.plot(X_plot, self.obj_fn(self.X_plot, noise=0), 'r--', label='True fn')
ax1.plot(X_plot, ei_trace['mu'], 'b-', label='EI surrogate mean')
ax1.fill_between(X_plot,
ei_trace['mu'] - 1.96 * ei_trace['sigma'],
ei_trace['mu'] + 1.96 * ei_trace['sigma'],
alpha=0.15, color='blue')
ax1.set_ylabel('EI surrogate', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
ax1_twin.plot(X_plot, pi_trace['mu'], 'g-', label='PI surrogate mean')
ax1_twin.fill_between(X_plot,
pi_trace['mu'] - 1.96 * pi_trace['sigma'],
pi_trace['mu'] + 1.96 * pi_trace['sigma'],
alpha=0.15, color='green')
ax1_twin.set_ylabel('PI surrogate', color='green')
ax1_twin.tick_params(axis='y', labelcolor='green')
# shared initial samples
ax1.scatter(self.X_train_init, self.y_train_init, c='black', zorder=10, label='Initial samples')
# EI and PI proposed samples from previous iterations
if i > 0:
ei_new_X = ei_trace['X_train'][len(self.X_train_init):]
ei_new_y = ei_trace['y_train'][len(self.X_train_init):]
ax1.scatter(ei_new_X, ei_new_y, c='blue', marker='^', zorder=10, label='EI samples')
pi_new_X = pi_trace['X_train'][len(self.X_train_init):]
pi_new_y = pi_trace['y_train'][len(self.X_train_init):]
ax1_twin.scatter(pi_new_X, pi_new_y, c='green', marker='s', zorder=10, label='PI samples')
ax1.axvline(x=ei_trace['X_next'], color='blue', linestyle='--',
label=f'EI next: {ei_trace["X_next"][0,0]:.2f}')
ax1.axvline(x=pi_trace['X_next'], color='green', linestyle='--',
label=f'PI next: {pi_trace["X_next"][0,0]:.2f}')
ax1.set_title(f'Surrogate - Iter {i+1}')
if i == 0:
lines1, labels1 = ax1.get_legend_handles_labels()
lines1_twin, labels1_twin = ax1_twin.get_legend_handles_labels()
ax1.legend(lines1 + lines1_twin, labels1 + labels1_twin, fontsize=7)
# --- combined acquisition plot with twin axis ---
ax2 = plt.subplot(n_iter, 2, 2 * i + 2)
ax3 = ax2.twinx()
ax2.plot(X_plot, ei_trace['acq_vals'], 'b-', label='EI')
ax2.axvline(x=ei_trace['X_next'], color='blue', linestyle='--')
ax2.set_ylabel('EI', color='blue')
ax2.tick_params(axis='y', labelcolor='blue')
ax3.plot(X_plot, pi_trace['acq_vals'], 'g-', label='PI')
ax3.axvline(x=pi_trace['X_next'], color='green', linestyle='--')
ax3.set_ylabel('PI', color='green')
ax3.tick_params(axis='y', labelcolor='green')
ax2.set_title(f'Acquisition - Iter {i+1}')
if i == 0:
lines2, labels2 = ax2.get_legend_handles_labels()
lines3, labels3 = ax3.get_legend_handles_labels()
ax2.legend(lines2 + lines3, labels2 + labels3)
plt.show()
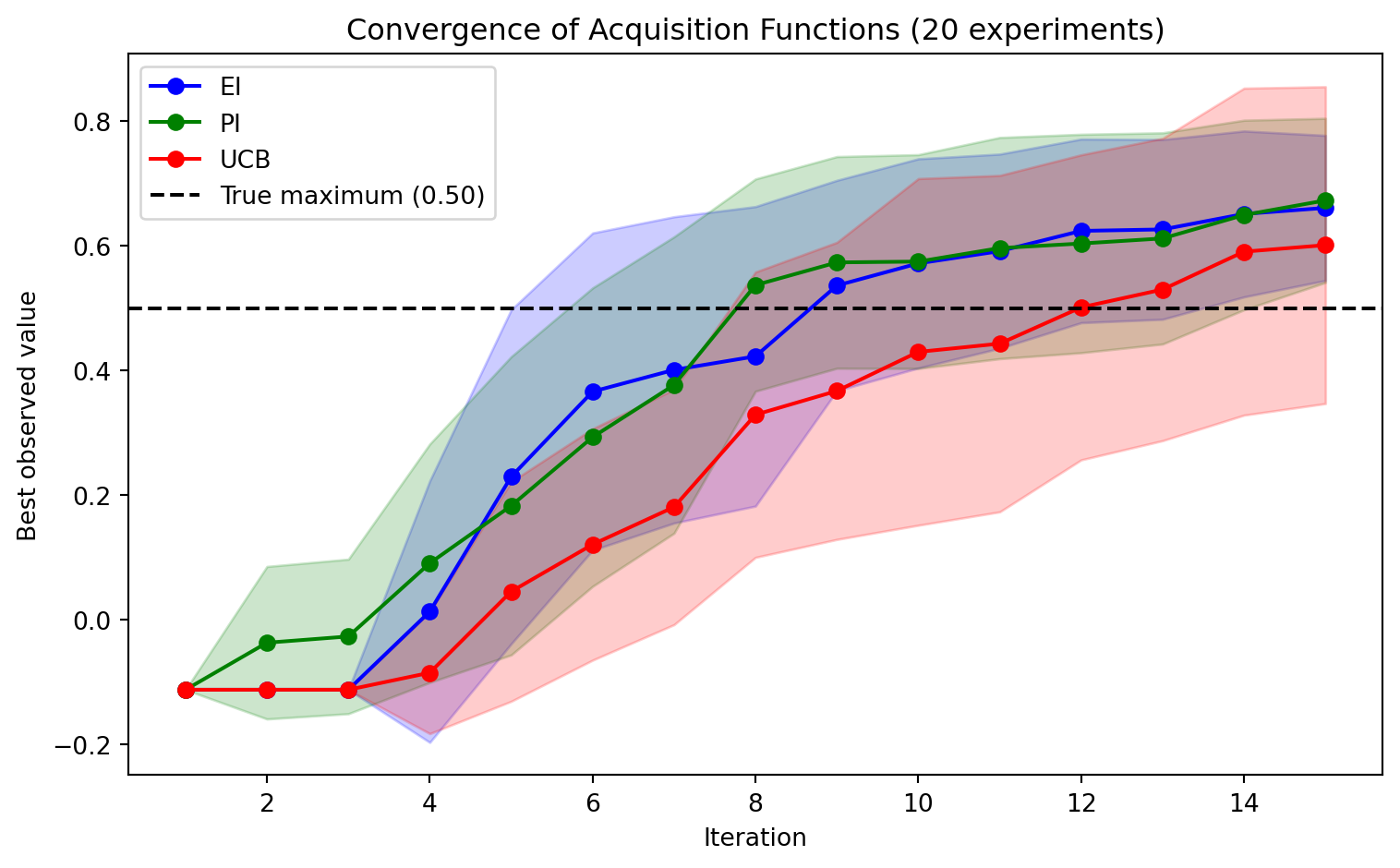
def convergence_plot(self, n_iter, n_experiments=20, n_restarts=5):
"""
Plot the convergence of EI, PI, and UCB acquisition functions.
Runs the BO loop for each acquisition function n_experiments times
from different random seeds and plots the mean and standard deviation
of the best observed value at each iteration.
Args:
n_iter: Number of BO iterations per experiment.
n_experiments: Number of random experiments to average over.
n_restarts: Number of restarts for propose_location.
"""
results = {'EI': [], 'PI': [], 'UCB': []}
for seed in range(n_experiments):
np.random.seed(seed)
traces_ei = self.run_bo(self.expected_improvement, n_iter, store_traces=True, n_restarts=n_restarts)
traces_pi = self.run_bo(self.improvement_probability, n_iter, store_traces=True, n_restarts=n_restarts)
traces_ucb = self.run_bo(self.upper_confidence_bound, n_iter, store_traces=True, n_restarts=n_restarts)
def best_observed(traces):
return [np.max(t['y_train']) for t in traces]
results['EI'].append(best_observed(traces_ei))
results['PI'].append(best_observed(traces_pi))
results['UCB'].append(best_observed(traces_ucb))
iterations = np.arange(1, n_iter + 1)
colors = {'EI': 'blue', 'PI': 'green', 'UCB': 'red'}
plt.figure(figsize=(8, 5))
for name, runs in results.items():
runs = np.array(runs)
mean = runs.mean(axis=0)
std = runs.std(axis=0)
plt.plot(iterations, mean, '-o', color=colors[name], label=name)
plt.fill_between(iterations,
mean - std,
mean + std,
alpha=0.2, color=colors[name])
true_max = np.max(self.obj_fn(self.X_plot, noise=0))
plt.axhline(y=true_max, color='black', linestyle='--',
label=f'True maximum ({true_max:.2f})')
plt.xlabel('Iteration')
plt.ylabel('Best observed value')
plt.title(f'Convergence of Acquisition Functions ({n_experiments} experiments)')
plt.legend()
plt.tight_layout()
plt.show()